
了解一波爬虫技术

前言
目前笔者所在的公司有相当一部分数据来源是从网络上爬取的,也有专门的爬虫团队进行数据的抓取和数据源的整理和收集。后续的流程再进行进一步的清洗、关联、分析。最终形成有价值的数据。在这一流程中, 尽管数据的分析技术比较重要, 但是了解上游数据的来源和数据抓取的机制,将利于对业务的理解,写出更加健壮高效的实时、离线处理程序。
Python入门
python的基础知识这里就不详述了,基本上一两天就可以入门,最好的学习还是放在实践中去驱动,比如写第一个爬虫。首先要了解的是基本语法结构,比如常用的数据结果,字符串、列表、字典等。然后就是for循环、函数的定义和调用、类的创建与初始化等…
基本语法
变量赋值:使用等号(=)将值赋给变量,例如:
x = 10数据类型:Python支持多种数据类型,包括整数、浮点数、字符串、列表、元组、字典等。
条件语句:使用if、elif和else关键字进行条件判断,例如:
1
2
3
4
5
6if x > 10:
print("x is greater than 10")
elif x == 10:
print("x is equal to 10")
else:
print("x is less than 10")循环语句:Python提供了for和while循环语句,可以用于遍历序列、迭代器和字典等数据结构,例如:
1
2
3
4
5for i in range(10):
print(i)
while x < 100:
x += 10函数定义:使用def关键字定义函数,例如:
1
2def add(x, y):
return x + y
其他的语法还有很多……对于有Java语言背景的同学,可以着重注意下:
Python是强制缩进的,不需要括号和分号。
在Java中,必须显式声明变量的数据类型,而在Python中,变量的数据类型是根据其值自动推断的。数据类型更加灵活,列表里可以有不同类型的元素。
Python和Java都支持基本的算术、比较和逻辑运算符,但是它们的运算符有一些不同之处。例如,Python中的除法运算符
/会返回浮点数结果,而Java中的除法运算符/会截断为整数。Python和Java都支持异常处理,但是它们处理异常的方式有所不同。在Python中,使用
try-except语句来处理异常,而在Java中,使用try-catch语句来处理异常。
爬虫入门
爬虫是一种自动化程序,可以在互联网上自动抓取和解析网页数据。通常,爬虫会从一个起始点开始,然后依次遍历网页链接,抓取网页内容并提取有用的信息,如文本、图像、视频等。爬虫可以被用于各种场景,如搜索引擎、数据挖掘、舆情监测、电商竞品分析等。

爬虫从本质上来说,就是可以发起请求的自动化程序。可以模拟人在浏览器中的行为,自动抓取信息并保存下来。而对于网站来说,目前主要分为两种,静态页面和动态页面。以动态页面为主。目前绝大多数数据都是服务器动态加载的。对于静态页面,就是采用各种技术(如正则表达式、XPath、CSS选择器等)从网页中提取所需的信息。而动态数据,可能会涉及到一些反爬的机制,比如验证码、混淆加密的JS、接口的加密等等。而这类数据才是目前爬虫与反爬技术相互切磋的主要阵地。无论何种方式,始终要注意爬虫程序对网站的访问影响,合理的请求,否则就真的可能“面向监狱编程了”。
了解这些之后,我们需要学习一下下面这几个库的使用:
import requests
from bs4 import BeautifulSoup
import re
requests是一个Python第三方库,用于发送HTTP请求和处理响应。它提供了一种简单、优雅的方式来发送HTTP/1.1请求。支持GET、POST、PUT、DELETE等请求方法,以及HTTP基本认证、Cookie、SSL等常见功能。使用requests库,可以快速、方便地编写Python爬虫、Web应用程序等。以下是一个使用
requests库发送GET请求的示例代码:1
2
3
4
5
6
7import requests
response = requests.get('https://www.baidu.com')
print(response.status_code) # 打印响应状态码
print(response.text) # 打印响应内容示例代码中,我们使用
requests库发送了一个GET请求到百度并打印了响应状态码和响应内容。使用requests库发送POST、PUT、DELETE等请求方法也类似,只需要将requests.get替换为对应的方法即可。Beautiful Soup 4(简称为bs4)是Python的一个HTML和XML解析库,它可以将复杂的HTML和XML文档转换成容易操作的Python对象。使用Beautiful Soup,遍历文档树,搜索文档树中的标签、字符串和属性,以及修改文档树的内容。示例如下:
1
2
3
4
5
6
7from bs4 import BeautifulSoup
html_doc = ""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())Python的re库是一个用于正则表达式操作的库。正则表达式是一种用于匹配字符串的模式,它可以用于搜索、替换和分割字符串。re库提供了一组函数,可以使用正则表达式进行字符串操作。提取数字的示例如下:
1
2
3
4
5
6
7
8import re
string = ''
pattern = r'\d+'
match = re.findall(pattern, string)
print(match)
爬虫实例demo
下面找个大家都喜欢看的图片类型网址进行爬取😆 
首先分析一下网址的源码结构,目的是找到图片地址的获取方式。
这一步非常重要,否则后面的步骤无法进行下去。直接F12(如果F12发现无法进行查看,需要绕过网址浏览器的检测、或者直接 view-source:url)
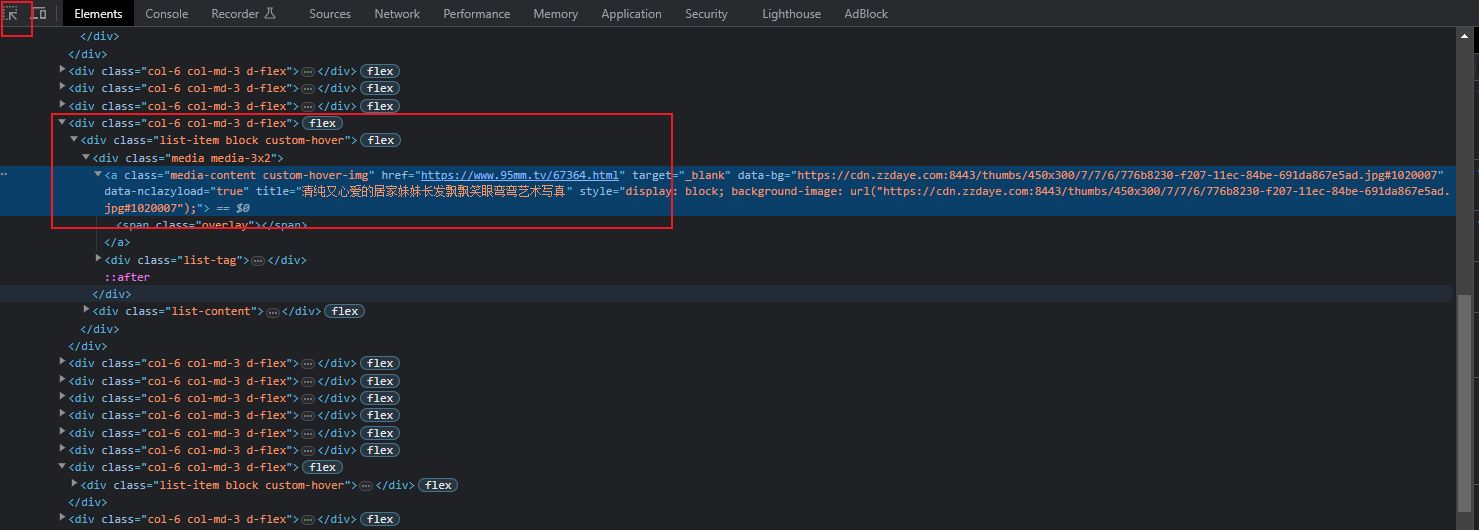
已知该网站的div结构下的a标签带有图片的详情地址,class=media-content custom-hover-img 记下这个路径,后续用的上。
点击进入详情页, 发现页面只有一张图片,并没有分页的接口地址或者请求。 仔细向下寻找发现,所有的图片地址隐藏在一段JS脚本中。
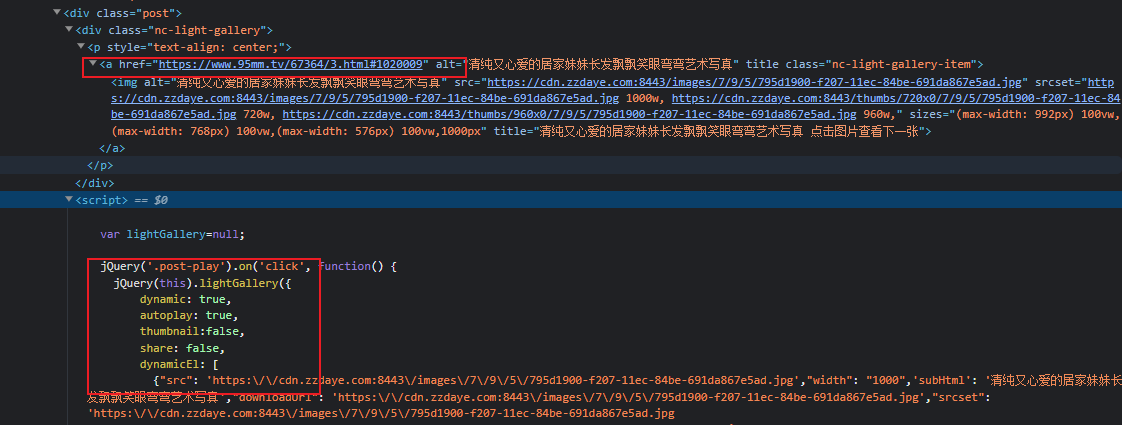
需要获取这个详情页的script,然后通过正则拿到所有的src.另外通过观察发现, 这些url是需要转义的,需要我们进一步处理,处理完毕,就得到了真实的图片URL地址了.
分析完就是coding和debug了。遇到问题多调试几次。开始代码编写的时候需要注意请求头的设置,否则会被网站拒绝访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70import requests
from bs4 import BeautifulSoup
import re
import hashlib
import os
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
def solve_main_page(url):
resp = requests.get(url=url, proxies=proxies, headers=header)
# print(resp.text)
# 使用Xpath进行解析
html = etree.HTML(resp.text)
a_list = html.xpath('//*[@id="dg_list"]/div/div/div[1]/a')
dict_list = []
for al in a_list:
dict_list.append({'div_href': al.get('href'), 'div_title': al.get('title')})
# print(al.get('href'))
return dict_list
def solve_dict_detail_single(dict_entity):
url = dict_entity['div_href']
title = dict_entity['div_title']
resp = requests.get(url=url, proxies=proxies, headers=header)
# print(resp.text)
soup = BeautifulSoup(resp.text, "html.parser")
div_p = soup.find("div", class_="post")
# dir_alt = div_p.find("a", class_="nc-light-gallery-item")
div_script = div_p.find("script")
# 匹配以src开头,以jpg结尾的文本
regex = r'\"src\":(.*?)\.jpg'
# 使用re.search()方法查找并返回匹配的子字符串
match = re.finditer(regex, div_script.text)
for i in match:
txt_url = i.group(1).strip()[1:] + '.jpg'
# 去除转义后的图片url
quote_url = txt_url.replace("\\", "")
# 下载图片
pic_resp = requests.get(quote_url, proxies=proxies, headers=header)
# 创建文件夹
path_dir = "pic/" + title + "/"
if os.path.exists(path_dir):
pass
else:
os.makedirs(path_dir)
with open(path_dir + md5(quote_url) + ".jpg", mode="wb") as fw:
fw.write(pic_resp.content)
print("下载<" + title + ">完毕")
if __name__ == '__main__':
url= "https://www.95mm.tv/67364.html"
#print(url)
set_rp = solve_main_page(url)
#print(set_rp)
with ThreadPoolExecutor(5) as t:
for ss in set_rp:
print(ss)
t.submit(solve_dict_detail_single, ss)
print("执行完毕")执行完毕。爬取的结果如下。理论上从入口页开始遍历,然后循环整个类别可以下载该网站所有的图片,不过学习交流的目的,还是尽量避免对服务造成压力。

后续计划
web逆向。该网站比较简单,后面继续考虑爬取一些需要解密才能获取数据的网站。
异步协程。多线程的访问依然是同步进行的,效率不高,可以采取异步HTTP请求+异步IO的方式,更加高效的获取数据。
了解爬虫开发框架Scrapy,了解企业级爬虫开发项目的构建开发方式




