
数据流处理之API设计_翻译文章
数据流API设计
原文:https://jenkov.com/tutorials/data-streaming/stream-processing-api-designs.html
数据流处理作为一种接收实时产生的事件(记录)并立即处理的技术已经变得非常流行。使用流处理(Aka数据流)有很多好处和用例。因此设计者开发了多种流处理 的API 来帮助开发人员更加轻松地处理流程序。
从表面上看,这些流处理 API 较为相似。不过一旦你尝试使用这些 API 来实现复杂的流处理逻辑,你就会意识到这些 API 的设计大大简化了使用它们处理流的复杂性。即使是设计上的细微差别也会对实现的内容产生影响,尤其是实现起来的难易程度。
在接触过各种流处理 API 之后,我决定写这篇流处理 API 接口设计的方案分析。帮助即将涉足流处理的或者希望在流处理 API 时寻求一些指导的人。
流处理API设计概念
在开始设计分析之前,我想列出我已经意识到的流处理 API 设计的重要方面。这些设计方面是:
拓扑
信息流
转向
触发器
状态
反馈
并发模型
我将在以下部分探讨不同的设计选项及其结果。
拓扑
流处理设计中更常见的设计选择之一是将流处理组件构建为一起工作的组件图。每个组件获取一条记录,对其进行处理,可能对其进行转换,然后将 0、1 或更多记录输出到图中的以下组件。以下是此类流处理拓扑的简单示例说明:
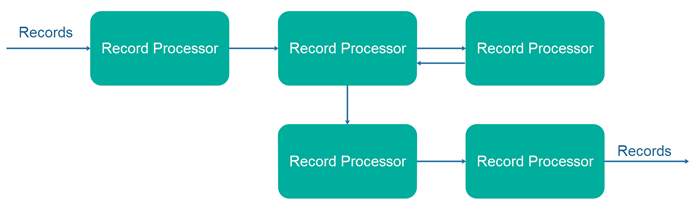
这种流处理 API 设计的最初动机来自于轻松处理大量对象或记录的 API,例如 Java Stream API。
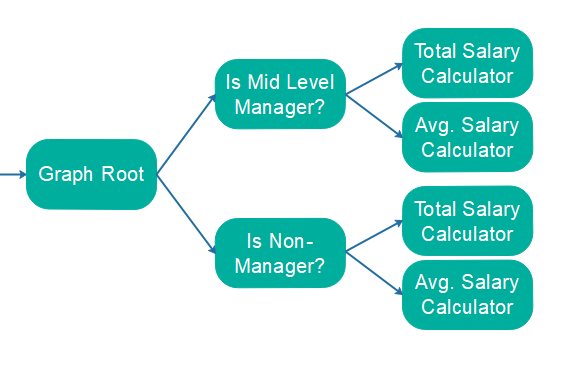
举个例子: 想象在一个列表中存放了数百万个 Employee 对象(或记录)。你需要:
找到所有中层管理者
计算他们薪水的平均值和总值
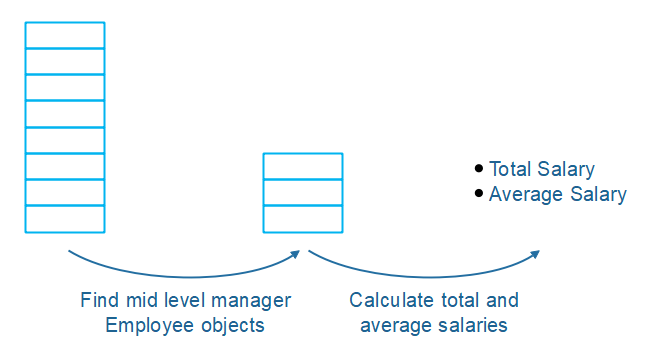
首先,你需要迭代所有 Employee 对象一次,目的是为了找到所有符合条件的 Employee 对象。其次,你必须再次迭代符合条件的 Employee 对象列表,并同时执行平均值和总值的计算。最后,您将迭代超过原始元素列表(原始+过滤列表)。
现在想象一下,您需要执行相同的计算,但这次是针对代表非经理的 Employee 对象。同样,首先您需要遍历整个 Employees 列表以找到匹配的 Employee 对象,找到这些对象后,遍历该列表并执行计算。
在上述 2 个要求的简单实现中,您将迭代原始列表 2 次(一次查找中层经理,一次查找非经理),并对每个筛选列表迭代一次。这是本质上相同对象的大量重复迭代! 相反,您可以构建一个对象处理图,对原始对象列表进行一次迭代,然后将每个对象传递给该图进行处理。以下是如何将上例中提到的计算结构化为图形:
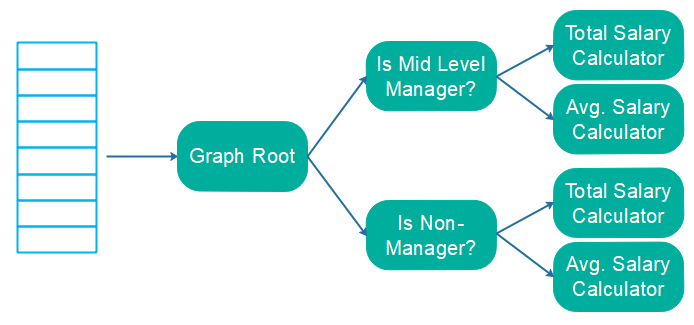
使用这种设计,对象只迭代一次。两个过滤器只会将相关记录转发给总工资和平均工资计算器。
流处理 vs. 批处理
当你想要处理一个存放了多个对象List时,面向拓扑的对象处理 API 非常有意义。对象的List也称为批处理。面向拓扑的设计意味着你只需迭代一次记录。API 通常也是可动态组合的,这使得实现不同类型的拓扑以满足不同的处理需求变得相当简单。
然而,在真正的流处理中,一次只有一个记录或对象。你永远不会像前面示例中所示那样以低效的方式实现迭代,因为一次总是只有一个对象要处理。不需要迭代。即使一次只有一条记录,你仍然可以使用面向拓扑的设计并获得可组合性优势。
然而,对于许多较小的处理要求,使用完整的面向拓扑的方法可能有点矫枉过正。一个可以计算所有的侦听器,而不是带有过滤器的将更容易实现,也可以表现得更好。
此外,如果拓扑变得太大,就很难推断出它在做什么,并且你可能无法提供支持拓扑的反馈,具体取决于你使用的面向拓扑设计的类型(基于功能还是基于观察者)。
这里没有明确的结论。 请记住,面向拓扑的设计在真正的流处理中并不总是像在批处理中那样有益。 根据你的流处理要求,让自己对可能的解决方案持开放态度。 基于拓扑的方法可能是合适的,也可能是矫枉过正。 但是,如果你只创建一个可以执行所有操作的侦听器/处理器,你可能仍然可以使用面向拓扑的 API 来实现简单的方法。
由于面向拓扑的流处理 API 设计既常见又流行,本文的其余部分将阐述基于拓扑设计的各个方面。
链 vs. 图
不同的面向图的流处理 API 设计是围绕不同类型的拓扑设计的。例如,Java Streams API 使用链式拓扑,如下所示:
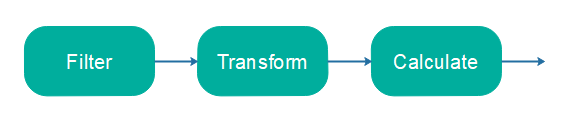
链式拓扑由单个处理器链组成,每个处理器接收一个对象或记录作为输入,并将一个对象或记录输出到链中的下一个处理器。在链的末尾,你只有一个结果。结果可以是多个子结果的组合,但它将包含在单个对象或记录中。
其他流处理 API 允许你创建更高级的处理器图。在处理流中的所有记录或对象之后,这样的图可以包含多个结果。这是本文前面的示例:
非循环图 vs. 循环图
几个面向图的流处理 API 只允许你创建一个无环图,这意味着记录最终只能在图中的一个方向流动。记录不能“循环”备份图表并重新处理。在许多情况下,循环图并不是执行所需操作所必需的,但偶尔循环图 API 可能会派上用场。
信息流
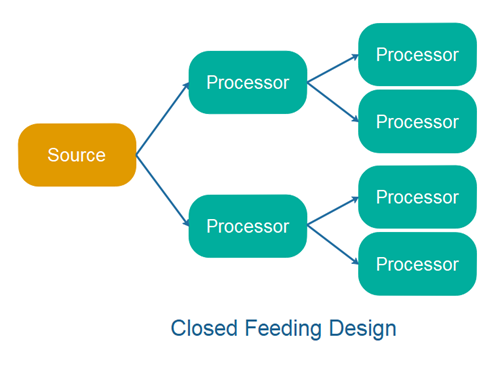
信息流是指流式处理 API 如何设计以将数据馈送到其处理拓扑中。例如,一些 API 有一个 Stream 的概念,你可以监听它,或者附加各种处理器来构建拓扑。但是不能直接将记录提供给源流。流被锁定以从特定源获取数据。例如。来自List或 Kafka 的Topic等。我将此称为封闭式信息流设计。
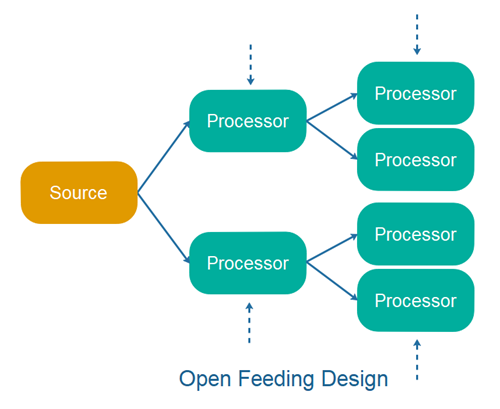
其他 API 使得在拓扑的每一步都可以轻松地将数据推送到拓扑中。在正常操作期间,这对于许多流处理用例来说可能不是必需的,但它对于某些用例以及测试期间可能非常有用。能够将数据推送到图中每个节点的拓扑中,使测试变得更加容易。我将此称为开放式信息流设计。
转发
转发是指流处理 API 如何在其流处理拓扑中将数据从一个处理器转发到下一个处理器。设计转发的方式有很多种,但通常的转发设计分为以下两类:
静态转发
动态转发
静态转发和动态转发不一定是难分的范畴。你可以拥有“半动态”(或“半静态”,具体取决于你选择的命名法)的设计。可以将这两个类别视为光谱的不同端点。 静态转发意味着给定的处理器只能将处理过的消息或消息处理的结果转发给一个(或多个)预定义的处理器。在创建拓扑时将其设为静态。一旦创建,拓扑是静态的(或至少难以更改)。 动态转发意味着给定的处理器可以自由选择将结果转发到哪个处理器(或后续处理器可以侦听的队列)。或者,至少它有更高的选择自由度,如果不是100%的自由选择也是可以的。
触发器
触发是指流处理 API 拓扑中的处理器如何被激活(触发)。触发机制往往属于以下类别之一
数据触发
非数据触发
数据触发是流处理 API 最常见的触发机制。数据触发意味着流处理拓扑中的处理器被通过它发送的数据触发。要处理的数据调用处理器方法,数据从那里流经拓扑。
非数据触发意味着基于非数据事件激活处理器。例如,您可能希望每 5 分钟调用一次处理器。那将是该处理器的基于时间的非数据触发。 非数据触发非常有用。例如,假设一个处理器在缓冲区中收集传入数据,然后每 60 秒将数据批量写入磁盘或数据库。如果您有稳定的数据流,您可以通过传入数据触发写入磁盘/数据库。但是,如果通过拓扑的数据流不稳定,则需要使用非数据触发器显式触发写入。
非数据触发也很有用 用于从您的处理器收集监控指标。 可以收集有关在给定时间段内通过每个处理器的消息/记录数量的信息。
状态
状态是指流处理 API 拓扑中的处理器的处理状态。状态保存在内存或者数据库中。
一些流处理 API 设计为仅供使用的无状态处理器。这通常适用于功能流处理设计 - 例如Java Streams API 和 Kafka Streams。请注意,即使这些 API 打算在其拓扑中使用无状态处理器,仍然可以插入有状态处理器。只是这些 API 的并发模型使用了共享状态并发设计——正是因为它们不希望它们的处理器有状态。因此,如果你插入一个有状态处理器,你必须自己确保状态访问的线程安全。 其他 API 旨在允许有状态处理器 - 例如通过使用单独的状态并发模型。有状态处理器违背了功能中的所有建议 (其中每个处理器只是一个无状态函数),但有状态处理器有时确实很有用。 能够在对处理器的调用之间在内部缓存对象可以提高性能。 例如,状态也是必要的。 计算拓扑中有多少条记录。
反馈
通过反馈,从拓扑中较晚的处理器返回到拓扑中较早的处理器。
想象一个由以下处理器组成的简单拓扑: 映射器:从 A 转换为 B。 过滤器:接受符合某些条件的 B 的第 10 个。 想象一下,从 A 到 B 的转换在 CPU 资源方面成本很高。在那种情况下,过滤转换后的 B 的过滤器能够通过拓扑提供反馈,告知 10 个 B 已被接受,因此不再需要将 A 转换为 B,这将很有用。以下是更改后的拓扑结构的外观:
过滤器 1:接受所有 A,除非另有通知。
映射器:从 A 转换为 B。
过滤器 2:接受符合某些条件的 B 的第 10 个。 B匹配10次后,通知Filter 1不再接受A。
要实现 at 拓扑,需要处理器可以是有状态的。 有状态处理器的替代方案是可以动态更改的拓扑 运行。 在上面的示例中,当过滤器 2 意识到不再需要将 A 转换为 B 时,可以添加过滤器 1。
并发模型
流处理 API 的并发模型是指如何设计 API 以在多个线程之间共享工作负载。正如我在并发模型教程中所解释的那样,有多种方法可以设计并发模型。当谈到流处理 API 时,通常拓扑的并发模型很重要。拓扑是使用共享状态还是分离状态并发模型?等等。
例如,流处理 API 可能设计为让多个线程执行相同的拓扑结构。这实质上导致了共享状态并发模型。 Kafka Streams 就是这样设计的。而且 - 这是一个烦人的设计。 或者,可以设计一个流处理 API 来为每个执行它的线程创建一个拓扑实例。
因此,每个线程都有自己的拓扑副本来执行。这导致了一个单独的状态并发模型。 重要的是你要准确地找出流处理的并发模型选择的 API 正在使用。 否则,可能会创建一个非线程安全的拓扑。




